

Introduction #
The LoveDA: Land-cOVEr Domain Adaptive Semantic Segmentation dataset was introduced to advance the fields of semantic learning and transferable learning. The LoveDA dataset comprises 5987 HSR images with 166768 annotated objects collected from three different cities, spanning both urban and rural domains. This diversity brings significant challenges, including multi-scale objects, complex background samples, and inconsistent class distributions. The LoveDA dataset is well-suited for tasks related to land-cover semantic segmentation and unsupervised domain adaptation (UDA).
Deep learning approaches have demonstrated substantial potential in the realm of high spatial resolution (HSR) land-cover mapping in remote sensing. Nevertheless, urban and rural environments often present significantly distinct geographical landscapes, posing challenges to the generalizability of such algorithms, especially in city-level or national-level mapping scenarios. Many existing HSR land-cover datasets primarily promote research into learning semantic representation, often neglecting the issue of model transferability.
Overview of the dataset distribution. The images were collected from Nanjing, Changzhou, and Wuhan cities, covering 18 different administrative districts.
The LoveDA dataset is a valuable resource for promoting large-scale land-cover mapping. Its key characteristics include multi-scale objects, complex background samples, and inconsistent class distributions, providing real-world complexity for researchers working on semantic segmentation and UDA tasks. By focusing on the style differences between geographical environments, LoveDA presents a distinct challenge in UDA compared to general computer vision datasets.
Image Distribution and Division
The LoveDA dataset was assembled from 0.3 m RGB images collected in Nanjing, Changzhou, and Wuhan, covering a total area of 536.15 km². This dataset consists of both urban and rural scenes, promoting diversity. Nine urban areas were carefully selected from economically developed districts characterized by high population density (>1000 people/km²). Concurrently, nine rural areas were chosen from less developed districts. After undergoing geometric registration and pre-processing, each area was represented by non-overlapping 1024 × 1024 images.
The LoveDA dataset is suitable for evaluating two primary tasks: Semantic Segmentation and UDA. For the first, eight areas are allocated for training, while the remainder are designated for validation and testing. These sets encompass both urban and rural regions. For the second, the UDA process addresses two cross-domain adaptation sub-tasks:
a) Urban to Rural: The source training set includes images from the Qinhuai, Qixia, Jianghan, and Gulou areas, while the validation set incorporates images from Liuhe and Huangpi. The test set contains images from Jiangning, Xinbei, and Liyang. The Oracle setting serves to test the upper limit of accuracy within a single domain, hence the training images originate from the Pukou, Lishui, Gaochun, and Jiangxia areas.
b) Rural to Urban: In this case, the source training set comprises images from the Pukou, Lishui, Gaochun, and Jiangxia areas. The validation set uses images from Yuhuatai and Jintan, with the test set utilizing images from Jiangye, Wuchang, and Wujin. These settings explore model adaptability between rural and urban environments, posing unique challenges for the UDA task.
It can be evaluated for two tasks: semantic segmentation and unsupervised domain adaptation (UDA). The data division ensures spatial independence among training, validation, and test sets for these tasks.
| Domain | City | Region | #Images | Train | Val | Test |
|---|---|---|---|---|---|---|
| Urban | Nanjing | Qixia | 320 | X | ||
| Urban | Nanjing | Gulou | 320 | X | ||
| Urban | Nanjing | Qinhuai | 336 | X | ||
| Urban | Nanjing | Yuhuatai | 357 | X | ||
| Urban | Nanjing | Jianye | 357 | X | ||
| Urban | Changzhou | Jintan | 320 | X | ||
| Urban | Changzhou | Wujin | 320 | X | ||
| Urban | Wuhan | Jianghan | 180 | X | ||
| Urban | Wuhan | Wuchang | 143 | X | ||
| Rural | Nanjing | Pukou | 320 | X | ||
| Rural | Nanjing | Gaochun | 336 | X | ||
| Rural | Nanjing | Lishui | 336 | X | ||
| Rural | Nanjing | Liuhe | 320 | X | ||
| Rural | Nanjing | Jiangning | 336 | X | ||
| Rural | Changzhou | Liyang | 320 | X | ||
| Rural | Changzhou | Xinbei | 320 | X | ||
| Rural | Wuhan | Jiangxia | 374 | X | ||
| Rural | Wuhan | Huangpi | 672 | X | ||
| Total | 5987 | 2522 | 1669 | 1796 |
Statistics for LoveDA
The dataset exhibits the largest number of labeled pixels and land-cover objects compared to other HSR land-cover datasets. The urban scenes in LoveDA contain diverse man-made objects, whereas rural areas are dominated by agricultural land. Spectral statistics show consistency in mean values and lower standard deviations for rural images, indicating more homogeneous areas. The presence of multi-scale objects necessitates models with multi-scale capture capabilities, particularly for large-scale land cover mapping tasks, thus increasing the challenge of model transferability in the face of varying urban and rural scenes.
 Homepage
Homepage Research Paper
Research Paper GitHub
GitHubSummary #
LoveDA: Land-cOVEr Domain Adaptive Semantic Segmentation is a dataset for a semantic segmentation task. It is used in the geospatial domain.
The dataset consists of 5987 images with 20658 labeled objects belonging to 7 different classes including background, road, building, and other: forest, water, agriculture, and barren.
Images in the LoveDA dataset have pixel-level semantic segmentation annotations. There are 1796 (30% of the total) unlabeled images (i.e. without annotations). There are 3 splits in the dataset: train (2522 images), test (1796 images), and val (1669 images). Alternatively, the dataset could be split into 2 areas: rural (2358 images) and urban (1833 images). The dataset was released in 2021 by the Wuhan University, China.
Here are the visualized examples for the classes:
Explore #
LoveDA dataset has 5987 images. Click on one of the examples below or open "Explore" tool anytime you need to view dataset images with annotations. This tool has extended visualization capabilities like zoom, translation, objects table, custom filters and more. Hover the mouse over the images to hide or show annotations.




























































Class balance #
There are 7 annotation classes in the dataset. Find the general statistics and balances for every class in the table below. Click any row to preview images that have labels of the selected class. Sort by column to find the most rare or prevalent classes.

Class ㅤ | Images ㅤ | Objects ㅤ | Count on image average | Area on image average |
|---|---|---|---|---|
background➔ mask | 4104 | 4104 | 1 | 35.46% |
road➔ mask | 3147 | 3147 | 1 | 6.48% |
building➔ mask | 3088 | 3088 | 1 | 12.49% |
forest➔ mask | 3043 | 3043 | 1 | 16.76% |
water➔ mask | 3004 | 3004 | 1 | 11.5% |
agriculture➔ mask | 2464 | 2464 | 1 | 38.75% |
barren➔ mask | 1808 | 1808 | 1 | 10.93% |
Co-occurrence matrix #
Co-occurrence matrix is an extremely valuable tool that shows you the images for every pair of classes: how many images have objects of both classes at the same time. If you click any cell, you will see those images. We added the tooltip with an explanation for every cell for your convenience, just hover the mouse over a cell to preview the description.
Images #
Explore every single image in the dataset with respect to the number of annotations of each class it has. Click a row to preview selected image. Sort by any column to find anomalies and edge cases. Use horizontal scroll if the table has many columns for a large number of classes in the dataset.
Object distribution #
Interactive heatmap chart for every class with object distribution shows how many images are in the dataset with a certain number of objects of a specific class. Users can click cell and see the list of all corresponding images.
Class sizes #
The table below gives various size properties of objects for every class. Click a row to see the image with annotations of the selected class. Sort columns to find classes with the smallest or largest objects or understand the size differences between classes.
Class | Object count | Avg area | Max area | Min area | Min height | Min height | Max height | Max height | Avg height | Avg height | Min width | Min width | Max width | Max width |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
background mask | 4104 | 35.46% | 100% | 0.01% | 6px | 0.59% | 1024px | 100% | 948px | 92.57% | 7px | 0.68% | 1024px | 100% |
road mask | 3147 | 6.48% | 64.25% | 0.01% | 5px | 0.49% | 1024px | 100% | 740px | 72.26% | 5px | 0.49% | 1024px | 100% |
building mask | 3088 | 12.49% | 86.87% | 0.01% | 6px | 0.59% | 1024px | 100% | 681px | 66.46% | 4px | 0.39% | 1024px | 100% |
forest mask | 3043 | 16.76% | 100% | 0.01% | 4px | 0.39% | 1024px | 100% | 727px | 71.02% | 8px | 0.78% | 1024px | 100% |
water mask | 3004 | 11.5% | 100% | 0.01% | 7px | 0.68% | 1024px | 100% | 688px | 67.16% | 7px | 0.68% | 1024px | 100% |
agriculture mask | 2464 | 38.75% | 100% | 0.01% | 8px | 0.78% | 1024px | 100% | 832px | 81.22% | 10px | 0.98% | 1024px | 100% |
barren mask | 1808 | 10.93% | 99.64% | 0.01% | 6px | 0.59% | 1024px | 100% | 554px | 54.15% | 9px | 0.88% | 1024px | 100% |
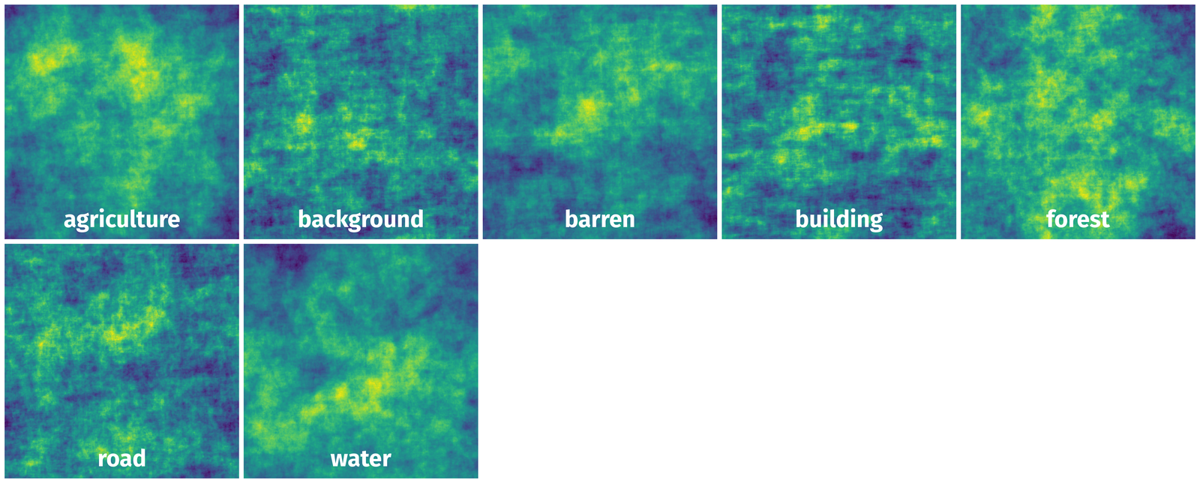
Spatial Heatmap #
The heatmaps below give the spatial distributions of all objects for every class. These visualizations provide insights into the most probable and rare object locations on the image. It helps analyze objects' placements in a dataset.
Objects #
Table contains all 20658 objects. Click a row to preview an image with annotations, and use search or pagination to navigate. Sort columns to find outliers in the dataset.
Object ID ㅤ | Class ㅤ | Image name click row to open | Image size height x width | Height ㅤ | Height ㅤ | Width ㅤ | Width ㅤ | Area ㅤ |
|---|---|---|---|---|---|---|---|---|
1➔ | background mask | 4126.png | 1024 x 1024 | 1024px | 100% | 919px | 89.75% | 20.69% |
2➔ | building mask | 4126.png | 1024 x 1024 | 266px | 25.98% | 452px | 44.14% | 6.63% |
3➔ | road mask | 4126.png | 1024 x 1024 | 1024px | 100% | 756px | 73.83% | 21.05% |
4➔ | water mask | 4126.png | 1024 x 1024 | 137px | 13.38% | 188px | 18.36% | 1.27% |
5➔ | forest mask | 4126.png | 1024 x 1024 | 90px | 8.79% | 121px | 11.82% | 0.68% |
6➔ | agriculture mask | 4126.png | 1024 x 1024 | 1024px | 100% | 1024px | 100% | 49.68% |
7➔ | background mask | 3937.png | 1024 x 1024 | 1006px | 98.24% | 819px | 79.98% | 8.43% |
8➔ | building mask | 3937.png | 1024 x 1024 | 6px | 0.59% | 64px | 6.25% | 0.03% |
9➔ | road mask | 3937.png | 1024 x 1024 | 167px | 16.31% | 1024px | 100% | 15.9% |
10➔ | water mask | 3937.png | 1024 x 1024 | 429px | 41.89% | 607px | 59.28% | 3.57% |
License #
LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation is under CC BY-NC-SA 4.0 license.
Citation #
If you make use of the LoveDA - A Remote Sensing Land-Cover data, please cite the following reference:
@inproceedings{NEURIPS DATASETS AND BENCHMARKS2021_4e732ced,
author = {Wang, Junjue and Zheng, Zhuo and Ma, Ailong and Lu, Xiaoyan and Zhong, Yanfei},
booktitle = {Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks},
editor = {J. Vanschoren and S. Yeung},
pages = {},
publisher = {Curran Associates, Inc.},
title = {LoveDA: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation},
url = {https://datasets-benchmarks-proceedings.neurips.cc/paper_files/paper/2021/file/4e732ced3463d06de0ca9a15b6153677-Paper-round2.pdf},
volume = {1},
year = {2021}
}
@dataset{junjue_wang_2021_5706578,
author={Junjue Wang and Zhuo Zheng and Ailong Ma and Xiaoyan Lu and Yanfei Zhong},
title={Love{DA}: A Remote Sensing Land-Cover Dataset for Domain Adaptive Semantic Segmentation},
month=oct,
year=2021,
publisher={Zenodo},
doi={10.5281/zenodo.5706578},
url={https://doi.org/10.5281/zenodo.5706578}
}
If you are happy with Dataset Ninja and use provided visualizations and tools in your work, please cite us:
@misc{ visualization-tools-for-remote-sensing-land-cover-dataset-dataset,
title = { Visualization Tools for LoveDA Dataset },
type = { Computer Vision Tools },
author = { Dataset Ninja },
howpublished = { \url{ https://datasetninja.com/remote-sensing-land-cover-dataset } },
url = { https://datasetninja.com/remote-sensing-land-cover-dataset },
journal = { Dataset Ninja },
publisher = { Dataset Ninja },
year = { 2024 },
month = { sep },
note = { visited on 2024-09-08 },
}Download #
Dataset LoveDA can be downloaded in Supervisely format:
As an alternative, it can be downloaded with dataset-tools package:
pip install --upgrade dataset-tools
… using following python code:
import dataset_tools as dtools
dtools.download(dataset='LoveDA', dst_dir='~/dataset-ninja/')
Make sure not to overlook the python code example available on the Supervisely Developer Portal. It will give you a clear idea of how to effortlessly work with the downloaded dataset.
The data in original format can be downloaded here:
Disclaimer #
Our gal from the legal dep told us we need to post this:
Dataset Ninja provides visualizations and statistics for some datasets that can be found online and can be downloaded by general audience. Dataset Ninja is not a dataset hosting platform and can only be used for informational purposes. The platform does not claim any rights for the original content, including images, videos, annotations and descriptions. Joint publishing is prohibited.
You take full responsibility when you use datasets presented at Dataset Ninja, as well as other information, including visualizations and statistics we provide. You are in charge of compliance with any dataset license and all other permissions. You are required to navigate datasets homepage and make sure that you can use it. In case of any questions, get in touch with us at hello@datasetninja.com.