

Introduction #
The authors of IITM-HeTra: Dataset for Vehicle Detection in Heterogeneous Traffic Scenarios emphasize the utility of video image processing from traffic camera feeds for tasks like counting and classifying vehicles, estimating queue length, determining traffic speed, and tracking individual vehicles. In contrast to homogeneous traffic, heterogeneous traffic involves various vehicle types that do not adhere to lane discipline, making vehicle detection particularly challenging, especially when vehicles are occluded, a common occurrence in such scenarios.
Recent advancements in Deep Learning have demonstrated significant potential in addressing various computer vision tasks, including object recognition, detection, and tracking. However, it’s worth noting that training deep learning models necessitates extensive labeled datasets, which are both time-consuming and expensive to obtain. To address this challenge, the authors propose a solution involving data augmentation. Specifically, they augment an existing large, general (non-traffic) dataset with a small, low-resolution dataset of heterogeneous traffic (collected by the authors themselves). This augmentation approach yields state-of-the-art vehicle detection performance. It’s important to highlight that, to the best of the authors’ knowledge, the dataset they collected, known as IITM-HeTra, represents the first publicly available labeled dataset for heterogeneous traffic.
To ensure that data are temporally uncorrelated, the authors of the study sampled a frame every two seconds from multiple video streams. A total of 2400 frames were extracted. 2400 frames were manually labeled under different vehicle categories by the authors. After careful scrutiny and elimination of unclear images, the number of available frames was reduced to 1417. The dataset was then divided by the authors into a trainval set (1202 images) and a test set (216 images), and this split was retained for all experiments. Initially, eight different vehicle classes commonly seen in Indian traffic were defined by the authors. Some of these classes were similar, while the two classes had fewer labeled instances; these were merged into similar-looking classes by the authors. For instance, in the dataset, there were different categories for small cars, SUVs, and sedans, which were merged under the “light motor vehicle (LMV)” category by the authors. The collected dataset contained a total of 6319 labeled vehicles. This included 3294 two-wheelers, 279 heavy motor vehicles (HMV), 2148 cars, and 598 autorickshaws. A second dataset was created by the authors by merging cars and autorickshaws together into the “light motor vehicle (LMV)” class. Approximately 25.2% of the vehicles were occluded, according to the authors.
Please note, that the original light motor vehicle (LMV) and cars classes are merged into a single cars class. heavy motor vehicles (HMV) class is renamed into bus, and two-wheelers is renamed to person respectfully.
 Homepage
Homepage Research Paper
Research PaperSummary #
IITM-HeTra: Dataset for Vehicle Detection in Heterogeneous Traffic Scenarios is a dataset for an object detection task. It is used in the surveillance industry, and in the vehicle detection domain.
The dataset consists of 1418 images with 6360 labeled objects belonging to 3 different classes including person, car, and bus.
Images in the IITM-HeTra dataset have bounding box annotations. All images are labeled (i.e. with annotations). There are 2 splits in the dataset: trainval (1202 images) and test (216 images). The dataset was released in 2018 by the IIT Madras, India.

Explore #
IITM-HeTra dataset has 1418 images. Click on one of the examples below or open "Explore" tool anytime you need to view dataset images with annotations. This tool has extended visualization capabilities like zoom, translation, objects table, custom filters and more. Hover the mouse over the images to hide or show annotations.




























































Class balance #
There are 3 annotation classes in the dataset. Find the general statistics and balances for every class in the table below. Click any row to preview images that have labels of the selected class. Sort by column to find the most rare or prevalent classes.

Class ㅤ | Images ㅤ | Objects ㅤ | Count on image average | Area on image average |
|---|---|---|---|---|
person➔ rectangle | 1229 | 3335 | 2.71 | 3.31% |
car➔ rectangle | 1127 | 2746 | 2.44 | 7.68% |
bus➔ rectangle | 253 | 279 | 1.1 | 8.59% |
Co-occurrence matrix #
Co-occurrence matrix is an extremely valuable tool that shows you the images for every pair of classes: how many images have objects of both classes at the same time. If you click any cell, you will see those images. We added the tooltip with an explanation for every cell for your convenience, just hover the mouse over a cell to preview the description.
Images #
Explore every single image in the dataset with respect to the number of annotations of each class it has. Click a row to preview selected image. Sort by any column to find anomalies and edge cases. Use horizontal scroll if the table has many columns for a large number of classes in the dataset.
Object distribution #
Interactive heatmap chart for every class with object distribution shows how many images are in the dataset with a certain number of objects of a specific class. Users can click cell and see the list of all corresponding images.
Class sizes #
The table below gives various size properties of objects for every class. Click a row to see the image with annotations of the selected class. Sort columns to find classes with the smallest or largest objects or understand the size differences between classes.
Class | Object count | Avg area | Max area | Min area | Min height | Min height | Max height | Max height | Avg height | Avg height | Min width | Min width | Max width | Max width |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
person rectangle | 3335 | 1.22% | 4.95% | 0.34% | 27px | 5.6% | 168px | 34.85% | 83px | 17.16% | 19px | 2.97% | 100px | 15.62% |
car rectangle | 2746 | 3.17% | 13.34% | 0.35% | 17px | 3.53% | 254px | 52.7% | 102px | 21.24% | 22px | 3.44% | 180px | 28.12% |
bus rectangle | 279 | 7.8% | 28.67% | 0.56% | 25px | 5.19% | 355px | 73.65% | 172px | 35.62% | 52px | 8.12% | 268px | 41.88% |
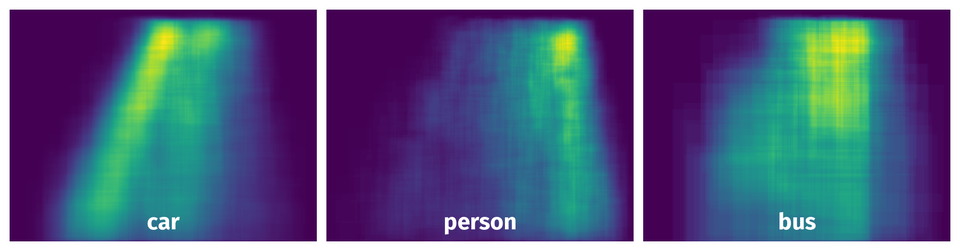
Spatial Heatmap #
The heatmaps below give the spatial distributions of all objects for every class. These visualizations provide insights into the most probable and rare object locations on the image. It helps analyze objects' placements in a dataset.
Objects #
Table contains all 6360 objects. Click a row to preview an image with annotations, and use search or pagination to navigate. Sort columns to find outliers in the dataset.
Object ID ㅤ | Class ㅤ | Image name click row to open | Image size height x width | Height ㅤ | Height ㅤ | Width ㅤ | Width ㅤ | Area ㅤ |
|---|---|---|---|---|---|---|---|---|
1➔ | person rectangle | frame_672.jpg | 482 x 640 | 124px | 25.73% | 61px | 9.53% | 2.45% |
2➔ | person rectangle | frame_672.jpg | 482 x 640 | 69px | 14.32% | 36px | 5.62% | 0.81% |
3➔ | person rectangle | frame_672.jpg | 482 x 640 | 71px | 14.73% | 30px | 4.69% | 0.69% |
4➔ | person rectangle | frame_672.jpg | 482 x 640 | 94px | 19.5% | 56px | 8.75% | 1.71% |
5➔ | person rectangle | frame_672.jpg | 482 x 640 | 74px | 15.35% | 34px | 5.31% | 0.82% |
6➔ | person rectangle | frame_672.jpg | 482 x 640 | 40px | 8.3% | 36px | 5.62% | 0.47% |
7➔ | car rectangle | frame_80.jpg | 482 x 640 | 130px | 26.97% | 73px | 11.41% | 3.08% |
8➔ | car rectangle | frame_80.jpg | 482 x 640 | 75px | 15.56% | 56px | 8.75% | 1.36% |
9➔ | person rectangle | frame_80.jpg | 482 x 640 | 78px | 16.18% | 43px | 6.72% | 1.09% |
10➔ | bus rectangle | frame_953.jpg | 482 x 640 | 59px | 12.24% | 102px | 15.94% | 1.95% |
License #
IITM-HeTra: Dataset for Vehicle Detection in Heterogeneous Traffic Scenarios is under GNU GPL 2.0 license.
Citation #
If you make use of the IITM-HeTra data, please cite the following reference:
@dataset{IITM-HeTra,
author={Deepak Mittal and Avinash Reddy and Gitakrishnan Ramadurai and Kaushik Mitra and Balaraman Ravindran},
title={IITM-HeTra: Dataset for Vehicle Detection in Heterogeneous Traffic Scenarios},
year={2018},
url={https://www.kaggle.com/datasets/deepak242424/iitmhetra}
}
If you are happy with Dataset Ninja and use provided visualizations and tools in your work, please cite us:
@misc{ visualization-tools-for-iitm-hetra-dataset,
title = { Visualization Tools for IITM-HeTra Dataset },
type = { Computer Vision Tools },
author = { Dataset Ninja },
howpublished = { \url{ https://datasetninja.com/iitm-hetra } },
url = { https://datasetninja.com/iitm-hetra },
journal = { Dataset Ninja },
publisher = { Dataset Ninja },
year = { 2026 },
month = { jul },
note = { visited on 2026-07-19 },
}Download #
Dataset IITM-HeTra can be downloaded in Supervisely format:
As an alternative, it can be downloaded with dataset-tools package:
pip install --upgrade dataset-tools
… using following python code:
import dataset_tools as dtools
dtools.download(dataset='IITM-HeTra', dst_dir='~/dataset-ninja/')
Make sure not to overlook the python code example available on the Supervisely Developer Portal. It will give you a clear idea of how to effortlessly work with the downloaded dataset.
The data in original format can be downloaded here.
Disclaimer #
Our gal from the legal dep told us we need to post this:
Dataset Ninja provides visualizations and statistics for some datasets that can be found online and can be downloaded by general audience. Dataset Ninja is not a dataset hosting platform and can only be used for informational purposes. The platform does not claim any rights for the original content, including images, videos, annotations and descriptions. Joint publishing is prohibited.
You take full responsibility when you use datasets presented at Dataset Ninja, as well as other information, including visualizations and statistics we provide. You are in charge of compliance with any dataset license and all other permissions. You are required to navigate datasets homepage and make sure that you can use it. In case of any questions, get in touch with us at hello@datasetninja.com.